Solving Data Sufficiency Issues in Machine Learning Projects (Part 2)
In my previous post on 'Data Sufficiency' issues in Machine Learning projects, I discussed how an Ontological approach may be able to solve (to a certain degree) to identify features or data points from a given data set, as long as we have a reference data set on which our models are build.
This process of extracting data points based on Ontological similarities or Semantic similarities could be termed as 'Data Reconciliation' phase. Please find the earlier post here.
In this post we shall try to see a little deeper and explore a technical approach on how to make Ontological comparisons as the basis of data reconciliation.
Let us see the following diagram:

The above figure basically elaborates the different phases involved in a typical Machine Learning project. Starting from the data model definition and creation of data sets (Feature Engineering), we go forward by testing different algorithms or ensembles and arrive at the most efficient one based on testing and evaluation.
The key scope of our problem in the context of data sufficiency is - how to create a master data set by reconciling the
available Data Sources and the Data Model. The two sub goals of our solution are:
a) All required data is
indeed available
b) Ambiguity is Managed
b) Ambiguity is Managed
Let's see, what steps are involved:

This is the step where we first extract meta data information from the data sources (prepared data) and create individual Ontologies and a merged version of the same. The purpose is to create a global Ontology (semantic representation) of the current state-of-the-art. The process will mostly be human assisted although scope of automation is there at appropriate stages as indicated.
On to the next step, we go and build a reference Ontology which is based on our existing model which we intend to apply to a new scenario, domain or organization.

The second step is to build a similar Ontology model of the reference data model that we have used in the machine learning project and wish to redeploy in a different context. As shown in the diagram, building this Ontology is a fairly automated process and benefits from predefined entity relationships and business glossaries which define the semantic meaning of the data entities, attributes and their inter relationships which are critical to build the 'graphical' model commonly associated with an Ontological representation. This we can call the Reference Ontology.
Once we have the Reference and Source Ontologies, the next step is to make an Ontological Comparison and Matching to discover potential matches and data entities which are similar. Not just in terms of what they are named as, data types but also structural similarities (we shall see that shortly).

The technical scope summarizes as: How to automate the process of Semantic Matching using Tools till the extent of getting candidate graph for each node? The key challenges that we may expect are:
a) How to detect Structural Similarities (Ancestors, Siblings, Descendants)
b) How match Language and Vocabulary
c) How to match Conceptual Similarities
d) How to detect Tactical Similarities, such as specific built for purpose data assets
In the next figure, we can try to summarize the schema of Ontological matching and arriving at 'candidate data entities' which match a reference (that is our model).
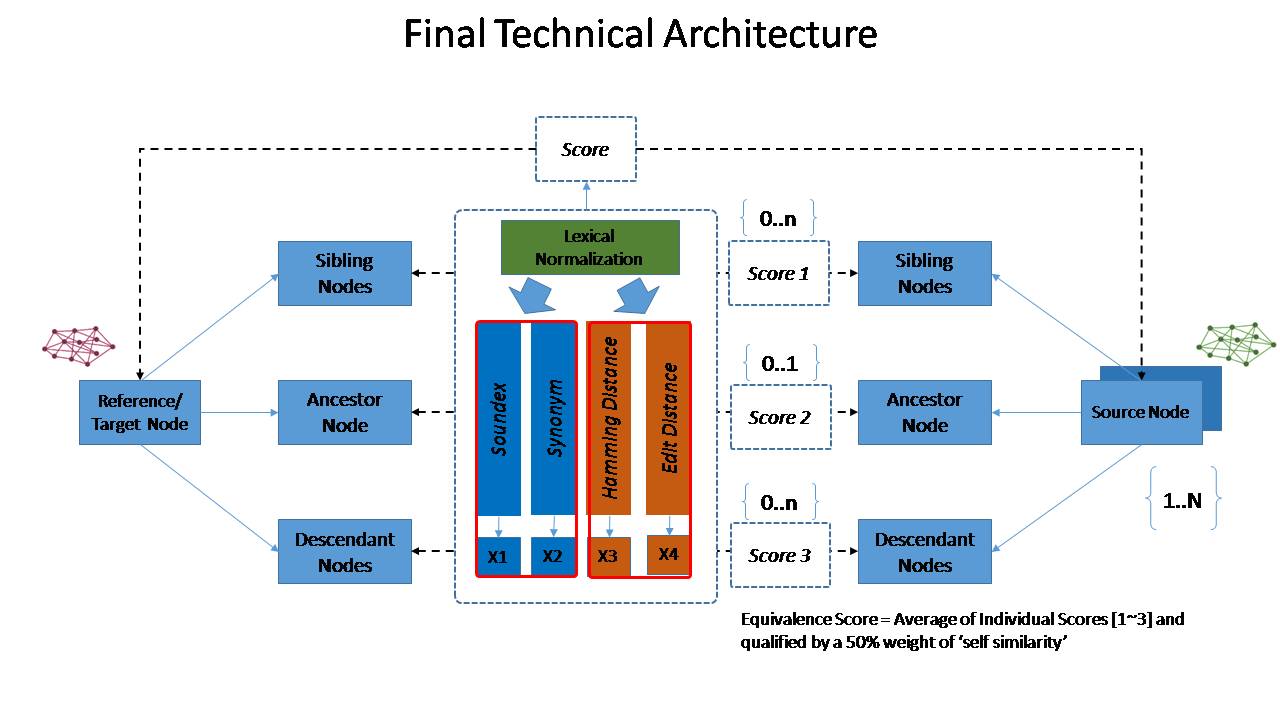
As we can see the process of matching is backwards. That is, from the reference to the source. We take into account the aspects such as the siblings, ancestors and descendants to measure the structural similarities between the nodes (data entities or attributes) and few Natural Language and String processing algorithms to measure the lexical and word similarities. In fact a combination of the following well known methods: Soundex, Synonym, Hamming and Edit distances may be enough to build a fairly useful matching rule without going into more powerful NLP methods.
The final output is a set of scores indicating the matches with siblings, ancestors and descendants which can be combined to create an overall score of matching.
Let us see the whole process through an example, albeit an hypothetical one. Let's say our Reference Ontology has a date element called 'Identity' with certain structural, linguistic and lexical properties. Whereas the Source Ontology may not have an exact match, it contains data entities such as 'Passport'. Although it is obvious that the elements associated with 'Passport' may very well match with 'Identity', both conceptually and structurally, how can a system of rules be developed which helps to do this automatically.

As we can see, the reference entity 'Identity' may match with multiple candidates like 'ID', 'Passport', 'Drivers License' and so on, while if different scores are taken into account, it exhibits a better 'Semantic Similarity' - a combination of structural, lexical and linguistic similarities - with 'Passport'.
In the end, going forward, I would recommend the following links for more detailed understanding about Ontology matching and how the concept can be applied in the context of Data Reconciliation.
Reference Material
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.62.8932&rep=rep1&type=pdf
http://eprints.biblio.unitn.it/531/1/015.pdf
http://www.semantic-web-journal.net/sites/default/files/swj56.pdf
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.62.8932&rep=rep1&type=pdf
http://eprints.biblio.unitn.it/531/1/015.pdf
http://www.semantic-web-journal.net/sites/default/files/swj56.pdf


Comments
Post a Comment